

What is Key Driver Analysis?
Key driver analysis is a powerful tool that uncovers the hidden factors that impact a specific target metric. By delving into both quantitative and qualitative data, this analysis allows you to unravel the mystery behind trends and gain valuable insights for taking immediate action or enhancing awareness within your organisation.
When analysing data there are several important targets that we often want to evaluate the influencers for. These targets include fields such as sales, customer satisfaction, margin, churned customers, and cost of sale. In order to understand the factors that drive these targets, we can look at examples such as product, location, store number, and manager. These key drivers play a crucial role in shaping the outcomes of these metrics and can provide valuable insights for decision-making within your organisation.
The metrics assessed in a key driver analysis vary from one organisation and use case to another. The specific target metric and the multitude of factors that influence its outcomes are contingent upon the problem you aim to resolve, the data at your disposal, and other relevant considerations.
Why use a Key Driver Analysis?
Key driver analysis in business intelligence is an invaluable tool that can be utilised in a multitude of ways to enhance key performance indicators. This analysis enables you to solve problems and gain valuable insights in areas such as product investment, revenue expansion, cost reduction, customer satisfaction, and more.
Within Qlik Sense, key driver analysis seamlessly integrates into the app consumer experience. Leveraging the real-time data analysis capabilities inherent in Qlik Sense, you have the power to initiate a fresh key driver analysis whenever the app data undergoes changes. This empowers you to constantly monitor your data for any shifts, swiftly uncovering emerging trends that require immediate and impactful action.

How does it work?
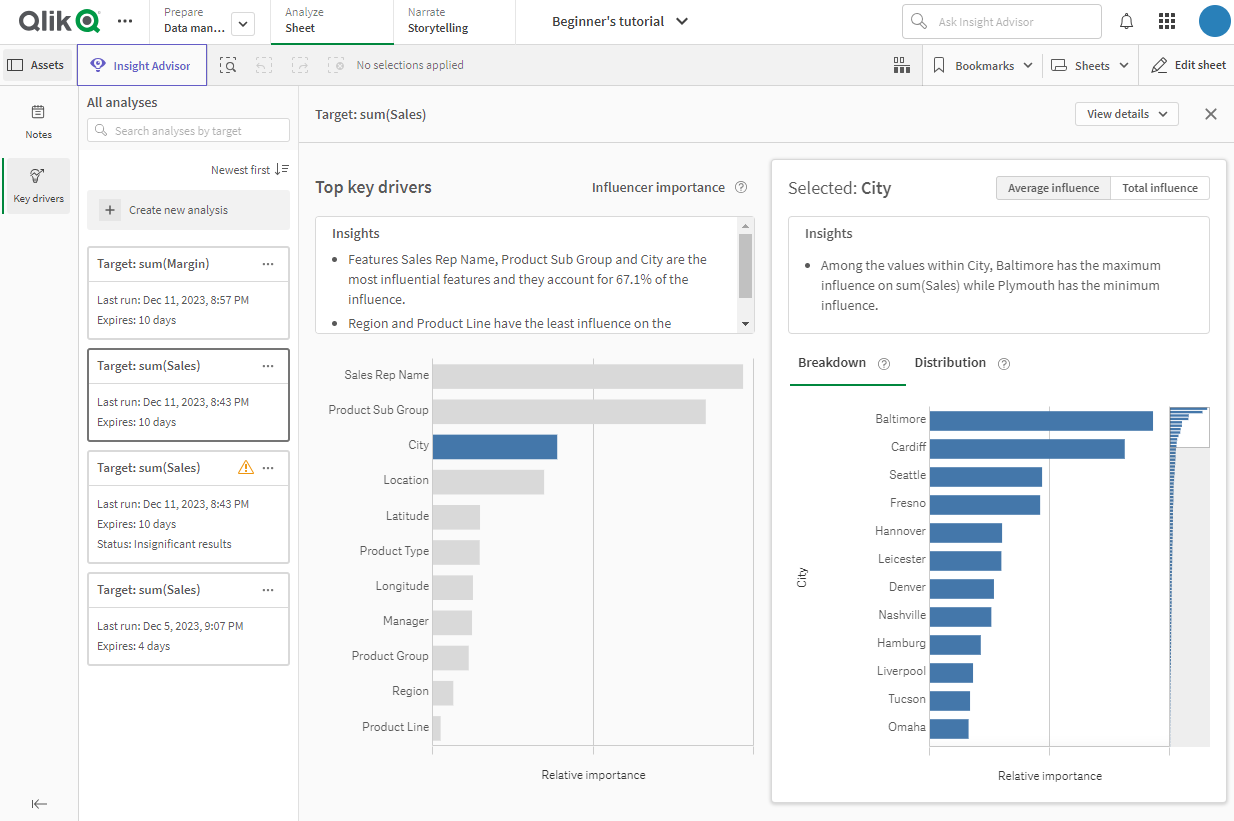
Key driver analysis revolves around the concept of influence. In the world of Qlik Sense, key driver analysis examines how specific fields (also known as features or key drivers) impact a particular field of interest, which is the target metric being analysed.
The data used in the analysis
A key driver analysis is a focused exploration of a portion of your data. When conducting this analysis, you choose specific fields to serve as the building blocks.
First choose the Target and Multiple feature building blocks. Once you have handpicked these components, a dedicated dataset is generated from your data model, specifically utilising the target and features. The key driver analysis then uses this dataset, rather than your entire data model, to determine the impact that the features have on the target metric. Any fields that you exclude from the configuration will not undergo analysis.
Calculating influence
In Qlik Sense, the key driver analysis process involves the calculation of Shapley (SHAP) values for each feature data value within the subset of data being analysed. These SHAP values are derived from a model that is trained using Qlik AutoML. Utilising the random forest algorithm, the model generates the SHAP values, providing valuable insights into the impact of each data value on the target metric.
The Shapley value is a powerful calculation that measures the extent to which a data value influences the corresponding target value, considering the interplay with other features in the specially created dataset for your key driver analysis. When you explore the results of a key driver analysis, you gain a comprehensive view of the aggregated impact of SHAP values across all records or a specific subset of the dataset.
For more information about SHAP importance in Qlik AutoML, see SHAP importance.
The target
The target metric is the focal point of key driver analysis, allowing you to delve into the factors that influence it. For instance, if you're interested in understanding how specific factors impact your sales, you would select a sales measure as your target. This enables you to gain valuable insights into the driving forces behind your sales performance.
When choosing your target metric, it is crucial to consider the availability of data over time, especially in relation to the specific features you include in your analysis. For further details on determining the appropriate timeframe for collecting data related to your target metric and features, please refer to the Features section below.
The uniqueness and nature of the data in the target metric play a significant role in determining the problem that the analysis will address. As a result, this also influences the specific requirements that your data must meet. For further details on the data requirements, please refer to the section on Data requirements later in this blog.
Key driver analysis supports the following problem types:
-
-
-
Regression
-
Binary classification
-
-
Regression analysis
When conducting a key driver analysis, regression analyses are utilised in situations where the target metric consists of numerous distinct numeric values. If your target metric is a numeric calculation or measure, the key driver analysis will interpret the configuration as a regression problem.
When selecting a metric as your focus, you have the option to apply a simple aggregation directly to the field in the configuration, or choose an existing master item if you prefer a more intricate expression.
Binary classification analyses
If your target metric consists of only two distinct values (such as "yes" or "no"), the key driver analysis identifies this configuration as a binary classification problem. By selecting a binary dimension as the target, you can create binary classification analyses. This allows you to uncover the underlying factors that drive these specific outcomes.
For instance, let's say you have a field in your app called "Churned" that tracks customers who have decided to cancel a specific service. In this case, you can choose the "Churned" field as your target metric to explore the underlying factors that influence these customer decisions. By doing so, you can gain valuable insights into what drives customers to churn and make informed decisions to mitigate churn in the future.

Features
The features serve as the driving force behind your analysis, uncovering the factors that influence trends in the data. For instance, when conducting a key driver analysis to identify the influencers behind sales, you have the flexibility to choose dimensions such as Location, Product Type, Store Number, and Sales Representative as your key drivers. Additionally, you can also utilise calculated measures as features, further enhancing the depth of your analysis.
It is crucial to include only those features in your analysis that have data that is recorded and collected prior to the collection of your target data. Including features that have data that you would only know at the time of collecting the target data can skew the analysis and render it devoid of analytical value.
As an illustration, if your focus is on sales performance, it is important to exclude any features that are directly derived from sales data. Similarly, when analysing customer churn with a binary outcome of "yes" or "no," it is advisable to avoid including the feature that indicates the specific date when the customer churned.
For more information about how to identify invalid analysis results, see Identifying invalid results.
Each feature in the analysis is categorized into one of two types: categorical features and numeric features.
-
Categorical feature: A categorical feature refers to data values that are grouped into distinct and recurring categories. For instance, consider the "Continent" field, where there are only a few possible values. In this case, these values are not treated as raw numeric data, but rather as text. It is also possible to use numbers as categories in certain instances.
-
Numeric feature: This refers to data values that are exclusively numerical and do not fall into any specific categories.
The analysis focuses on each included feature to determine the extent of its influence on the target metric's current data.
App selections
In the process of conducting a key driver analysis, the choices you make within the app directly impact the analysis. For instance, if your goal is to identify the key drivers for sales, you can choose to include the "Store Number" dimension as a feature. However, if you only want to focus on the influence of specific stores within your organisation, you have the flexibility to select and analyse just those five stores. By making these selections within the app, you can easily configure the key driver analysis to suit your needs and gain valuable insights.
As you make selections within the app to conduct your key driver analysis, it's crucial to keep in mind that these selections act as filters on the data model. This means that any choices you make in one field can have a direct impact on the data that is available for analysis. So, it's important to be mindful of how your selections may influence the results and ensure that you have the necessary data to gain valuable insights.
Data requirements
Minimum data volume requirements
To ensure successful analysis, it is essential that the dataset generated from your target and features contains a minimum of 400 cells. Without meeting this requirement, you will be unable to run the analysis and uncover valuable insights.
Other requirements
The following requirements apply to the dataset created from your analysis configuration:
-
The target needs to contain at least two unique values.
-
If the target contains between two and ten unique values, each unique value needs to appear in at least ten records in the dataset.
Next steps
To learn more about how Key Driver Analysis can bring value to your organisation, why not book a call with one of our team and take a look for yourselves?



Comments